
最近趁着业务重构,正好把日志收集系统也重构一下,之前用的版本还是es2.x的版本,实在太老了。最近看了看最新官方文档,发现好多新功能非常的实用,升级一波。
安装
首先在官网下载安装包,我下的是最新版本,官网上有各个历史版本的下载,随心下。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz系统配置
在这次安装里,我用了三台虚拟机,centOS6.5。当时7的镜像没准备好,其实感觉用7会更好一些。系统的配置主要是JDK配置、最大openfile数的配置等,并不复杂。
JDK:
export JAVA_HOME=~/elk/jdk1.8.0_74
export JRE_HOME=~/elk/jdk1.8.0_74/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
system_config:
vi /etc/sysctl.conf
vm.max_map_count = 655360
sysctl -p
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 65536
* hard nproc 131072接下来把下载好的安装包解压就好了,放在一个文件夹下,比较方便,比如~/elk。
配置
现在elastic stack的安装已经非常简便了,解压出来就好,配置上需要调整的地方也不多,看具体需求调整就好。
elasticsearch配置:
cluster.name: clusterName #es集群名
node.name: nodeName #es节点名,每个节点名字不同
path.data: ~/elk/data #es数据存放位置
path.logs: ~/elk/logs #es日志位置
bootstrap.memory_lock: false #这两个部分与系统有关,centos6需要设为false
bootstrap.system_call_filter: false
network.host: 0.0.0.0 #监听地址
http.port: 9288 #监听端口
discovery.zen.ping.unicast.hosts: ["es1_ip", "es2_ip", "es3_ip"] #把同一集群的所有节点的ip列在这里
discovery.zen.minimum_master_nodes: 2 #防脑裂的,设置成(nodeNumber+1)/2上面的这段配置是elasticsearch的配置。es是整套系统的核心组件,我用了三个节点的集群,健壮性得到了一定的保证。
具体到这次的配置,修改的部分不多,具体含义写在注释中了。除了这些配置外还可以配置比如es连接密码等,进一步提高安全性。
logstash的配置我没有修改,直接使用默认配置即可。
kibana配置:
server.port: 5601 #kibana监听端口,默认5600
server.host: "server_ip" #kibana的ip
server.name: "server_name"
elasticsearch.url: "http://localhost:9288" #es的连接地址
kibana.index: ".kibana" #kibana默认index关于kibana监听的ip地址,如果想直接ip:port就可以访问到,就配置成机器的外网ip;否则就设置成localhost,前面再加个nginx,这样的安全性会比较好,还可以通过nginx设置一个简单的权限验证,确保不是所有人都能够看到日志,毕竟有些日志也会涉及到一些敏感信息。
5.0版本以后的elastic stack引入了filebeat这一工具,这个组件代替了之前logstash收集日志的角色,使得logstash只专注于indexer的工作。而且filebeat在收集日志方面的可靠性和效率也比logstash高很多。之前的系统logstash收集者经常挂掉,导致日志收集不及时,数据也乱,还得专门写一个监控脚本来处理这个问题,filebeat目前我还没有发现有这个问题,运行比较稳定。
filebeat配置:
filebeat.prospectors:
- type: log
enabled: false
paths:
- /var/log/*.log
- type: log
enabled: true
paths:
- ~/nginx/logs/access.log
tags: ["webnginx"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
hosts: ["logstash.indexer_ip:port"]在之前2.x的时代,配置中最复杂的就是logstash收集、处理日志的部分;现在也差不多,只不过收集部分变成了filebeat。
filebeat的配置文件最重要的就是prospectors这个部分,这个部分下每一个-tpye下面的一段就是一个prospector,也就是收集者;一个配置文件中可以有若干个收集者。比如我上面的配置文件中配置了两个prospector,第一个是默认自带的,可以看到是收集/var/log文件夹下所有.log文件,只不过enabled项目设置成了false,也就是说并未启用。第二个prospector是我用来收集nginx日志的,可以给这条配置加上tag,这样在es中可以根据tag来筛选日志。
output部分可以输出到很多地方,可以直接输出到es中,也可以像上面那样输出到logstash.indexer中,还可以直接输出到标准输出,视需求而定。
另外,es、logstash、kibana三个组件的配置文件夹中都有jvm.options配置文件,可以配置jvm启动参数,比如扩大jvm内存等。之前2.x版本时修改es的jvm启动参数还需要修改启动脚本,现在方便了很多。
启动
四个组件的启动方式都比较简单,首先启动elasticsearch,核心组件当然要第一个启动:
~/elasticsearch/bin/elasticserach -d 之后启动logstash(indexer):
nohup ~/logstash/bin/logstash -f logstash-indexer.conf &接下来启动filebeat:
nohup ./filebeat -c filebeat.yml > /dev/null 2>&1 &最后启动kibana:
~/kibana/bin/kibana serve -p 5601 &kibana6.x版本应该是用node.js开发的,启动后是一个node进程,如果ps -ef|grep kibana是查不到kibana的进程的,如果要kill就搜索node。这个部分回头要是找到更好的重启方法再改吧。
至此elastic stack所有组件都启动完成了,确认下启动过程中没有报错,所有服务都在正常运行,就可以到浏览器中访问kibana,看下是否有收集到的日志了。
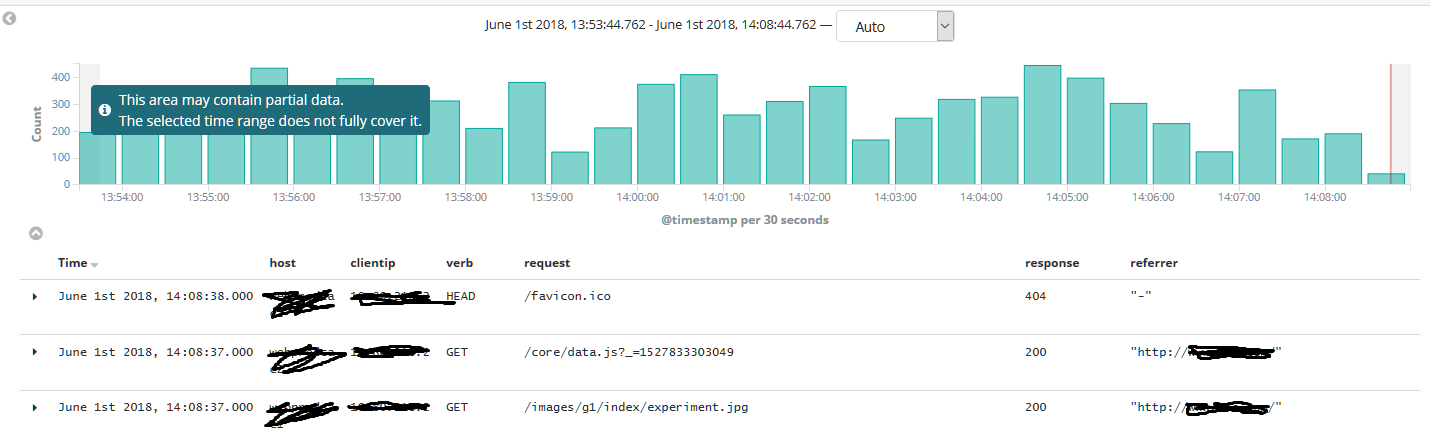
新版的kibana界面比原来好看很多,而且配合filebeat,功能也更完善了。好评!
上图的字段是经过logstash处理后拆分出来的字段,否则所有信息都在_source字段中,看起来不是很方便,下一篇文章我会写一下filebeat和logstash对于日志信息流的拆分处理。